












 ЇжоМ╦Ь╨цся
ЇжоМ╦Ь╨цся

OpenAI╦Ь©ф╪╪ппр╣гцоЛ╬╞жсё╛жп╧З╠ьпКр╙спвтжВ║╟ЄСдёпм║╠
уБ╡╩йгAI╣зр╩ЄнрЩфПххрИё╛тГтзAlphaGoЄР╟эхкюЮфЕйж╣дй╠╨Рё╛ппр╣╬м©╙фТ╧Щр╩╡╗“AIйгЇЯ╩Ах║ЄЗхкюЮ”╣д©ж╩ептлжбшё╛╣╚тзкФ╨С╣д╪╦дЙё╛AI╡╒ц╩сплЬЁЖхкюЮІткЭ╣др╩╧Ахож╙║ёж╠╣Ґ2022дЙё╛уБЄнё╛AI╡╩╣╚©ирт╨мхкюЮаВЁ╘╣ьадлЛё╩©иртя╦кы╩ьЄПхкюЮпХр╙й╝╪╦Їжжс╡едэ╩ьЄП╣дЄП╟╦ё╩дэя╦кы╪ЛкВхкюЮ©идэ╪╦п║й╠╡едэйу╪╞╣двйаоё╩╦ЭдэЄЄвВЁЖхцруйУ╪ртчл╬╣дсп“ЄЄтЛаі”╣д╩Ф╩ґ║ё
хк╧єжгдэ╧╚к╬OpenAIйгуБЁ║ххрИжп╣дҐ╧╣Цё╛кЭ╣дCEO Sam Altmanк╣ё╨“й╝дЙг╟╣дЄ╚мЁ╧ш╣Цхон╙ё╛хк╧єжгдэйвох╩Ас╟оЛлЕаіюмІ╞ё╛х╩╨Сйгхож╙юмІ╞ё╛тых╩╨Сё╛р╡пМспр╩лЛ©иртвЖЄЄтЛпт╧євВ║ёожтз©ЄфПюЄё╛кЭ╩АртоЮЇЄ╣дкЁпРҐЬпп║ё”ChatGPT╣диооъё╛╣ъ╦╡акхкюЮІтAI“гжу╪”хкюЮйюҐГ╣дхож╙║ёуБЁ║й╪сз╧Х╧х╣дAI╨ЙЄСпПйбё╛сисз╣мце╪В╣д╡нсКптё╛я╦кыЄЁхКфум╗хк╣диЗ╩Н║ёChatGPTвт2022дЙ11тбиооъртюЄё╛хк╧єжгдэ╧╚к╬Open AI╣д╧юж╣ря╬ґ╦ъЄО290рзцют╙║ё©ф╪╪╬чмЇхГаыЄС╣п║╒AIЄЄр╣╧╚к╬діхґ╡ауф║╒фум╗хктзсКAI╣дадлЛжпё╛мФ╣д╡╩рЮюж╨У║ё
м╛й╠ё╛р╩о╣апнйлБр╡╠╩ЄЬ╣Ґакхкцг╣дцФг╟ё╨
║Я иЗЁийҐAI╪╪йУё╛йгЇЯ╩АЄЬюЄр╩Ё║©╟╠хрфІ╞╩╔а╙мЬ╣дпбилр╣юкЁ╠ё©
║Я уБйгЇЯ╩А╦Ьд©г╟╣дилр╣╦Я╬жЄЬюЄ╬чЄС╣д╦д╠Дё©
║Я иЗЁийҐAIхЭ╣юё╛╣Ґ╣вспддп╘илр╣дёйҐ©иртмз╬Рё©
║Я жп╧З╣дмЇ╡©©ф╪╪фСр╣ё╛в╔в║уБЁ║пб╣дAIюкЁ╠акбПё©
║Я ╦ъІкп╬ф╛╠╩очё╛жп╧З╩╧сп©идэЇ╒у╧вт╪╨╣дAIЄСдёпмбПё©
лзяІ©ф╪╪Іт╩╟х╚гР©ф╪╪ЄЄпб╡Зр╣в╗╪р║╒©ф╪╪мІвйхкё╛╨ёрЬвй╠╬ЄЄй╪╨о╩ОхкмУЛох╚ё╛╦Ы╬щкШЁёдЙІтх╚гР©ф╪╪╡Зр╣╣д╧ш╡Л╪╟гвиМй╣╪Ыё╛Ё╒йт╩ьЄПртиодяҐБ╣днйлБ║ёуБп╘нйлБ╡╩╩Асп╠Йв╪ЄП╟╦ё╛╣╚йгнрцгоёмШдэЄсппр╣иНІх╡нсКуъ╣дІЮҐгІх╧ш╡Лжпё╛╦Ь╧ьв╒“иЗЁийҐAI”╣дІауъё╛ЄЬюЄр╩п╘фТЇ╒║ё
01
AIиЗЁиё╛╠ьІ╗рЩфП©ф╪╪╬чмЇ╣джьйс
Q1ё╨иЗЁийҐAIн╙╨нрЩфП©ф╪╪╬чмЇ╣д╧ьв╒ё©
мУЛох╚ё╨╣зр╩ё╛AI╩Ф╩ґ║╒ChatGPT╣хсісц╣дЁЖожё╛хцтҐюЄтҐІЮ╣дфум╗сц╩ї©иртй╧сцхк╧єжгдэ║ёцю╧З╬ґ╪цяї╪рDiego Comin╠МцВр╩╦Ж╬ґ╪цлЕ╣дг©хУ╡╩х║╬ЖсзкЭрЩхКохҐЬ©ф╪╪╣дкыІхё╛ІЬйгх║╬Жсзй╧сцохҐЬ©ф╪╪╣диНІх║ё
╠ххГ╩╔а╙мЬё╛╡╩Ї╒ЄО╧З╪ррЩхК╩╔а╙мЬ╣дкыІх╨э©Лё╛╣╚йгрЩхК╩╔а╙мЬ╨Сй╧сц╠хюЩ╣м║ё©ф╪╪ж╝кЫртдэмфІ╞иГ╩АЇ╒у╧ё╛йгрРн╙©ф╪╪дэ╠╩╧ЦЇ╨й╧сцё╛╧ЦЇ╨╣ьлАиЩпїбй╩РуъЄЬюЄпб╣ддэаіё╛хГ╧Шж╩йгспиыйЩхкй╧сцё╛кЭлАиЩпїбй╩РуъЄЬюЄпб╣ддэаі╩А╨эп║║ёкЫртOpenAIтзилр╣иолжбш╣дххІхйгмМсзсц╩їкЫлжбш╣дххІхё╛уБйг╠хҐоиы╪Ш╣дё╛кЫрт╨СюЄхк╧єжгдэ╩╟лБ╩Пххё╛йгкЁюМЁиубё╛к╝╣ҐгЧЁи╣д║ё
╣зІЧ║╒иЗЁийҐAIюЮсісц╦ЬнЄюЄЄЬюЄ╬чЄС╣доКоС©у╪Д║ёнрхон╙иЗЁийҐAI╩╧сп╨эІЮдёйҐЄЄпб╣д©у╪Дё╛тІц╩спЄО╣ҐвН╦ъ╣Ц║ёкДх╩ожтзря╬ґспхклҐкВакAIGC╣ддЁп╘й╧сцдёйҐё╛╣╚уБтІ╡╩йгжу╣Ц║ёль╠ПоЯ╣╠дЙ╣д╩╔а╙мЬё╛ЄсвНтГ╣дце╩їмЬу╬╣ҐмЬснё╛ты╣Ґ╣Гилё╛ты╣ҐхГҐЯІлйсф╣╣д╠╛╩Пё╛р╩ж╠тз╣ЭЄЗЇ╒у╧║ё

х╚гРйвюЩAIGC╪╪йУ╦╗жЗилр╣╩╞І╞╩ґф╛║Іх╝сКиыдЙ║Їё╛І╞╩ґЁ║╬╟сиAI╩Фжф
ІЬOpenAI╣д╪╪йУрю©©вт╪╨иХ╪ф╣ддёйҐ╬мдэ╧╩вЖЁЖ╦ЭІЮ╣дсісцё╛иУжак╣вЖЁЖ╦ЭЄС╦ЭЁи╧і╣дЄЄр╣╧╚к╬ё╛уБ╬мйгспоКоС©у╪Д║ё
ж╝г╟╣дхк╧єжгдэЄЄр╣╧╚к╬╨мЄЄй╪хкІ╪йгхк╧єжгдэв╗╪рё╛ожтзспакAIGC║╒Chat GPTё╛нрцг©идэжПҐ╔╩АЇ╒ожё╛╨эІЮхк╧єжгдэЄЄр╣╧╚к╬╣дЄЄй╪хк©ирт╡╩йг╪╪йУв╗╪р║ёкШ©иртохспр╩╦Жideaё╛х╩╨Стых╔урдЁн╩CTO╟ОкШй╣ожё╛ІЬгрCTOр╡╠хҐо╨цурё╛рРн╙спакуБп╘╩ЫЄ║╪╪йУё╛╟ОкШй╣ож╡╒╡╩дя║ёуБй╠╨Рхк╧єжгдэаЛсР╣дЄЄр╣╬м╩А╠Д╣д╩Нт╬ё╛р╡╬мйгкЫнҐ╣дмРжзЄЄпб║ёуБр╡йгкЭ╠╩ххрИ╣дтґрРж╝р╩ё╛хкцг╩Ахон╙уБ╪ЧйбюК“нр”╨эҐЭё╛ЁЩакдэ╧╩хуЁёй╧сцртмБё╛╦ЭжВр╙йгр╡пМ“нр”╬мдэЄЄр╣ё╛уБфДй╣Ґ╣╣макЄЄпбце╪Вё╛хц╦ЭІЮхкдэ╧╩╡нсКё╛╩Ай╧╣ц©ф╪╪ЄЄпбдэ╧╩╪с©ЛйпЁ║иЬм╦ё╛дэ╧╩й╧ЄЄпб╣д╪шж╣╠╩м╧отЁЖюЄё╛уБІ╪йгль╠ПспрБрЕ╣д║ё
Q2ё╨хГ╨н©ЄЄЩюоеф©ф╪╪╬чмЇн╒хМ╨мOpenAI╣д╨овВё©
мУЛох╚ё╨╣зр╩ё╛Ґ╣╣мкЦаіжїЁЖё╨ІтOpen AIюЄк╣ё╛кЦаійг╨эЄС╣дЁи╠╬ё╛рРЄкё╛кЭя║тЯ╨мн╒хМ╨овВ©иртЄСЇЫҐ╣╣мкЦаіжїЁЖё╩╣зІЧё╛нЄюЄтф╪фкЦ║╒хк╧єжгдэ║╒ЄСйЩ╬щҐ╚╩АиНІхҐА╨оё╛ІЬЄСа©╣дхк╧єжгдэсісцйг╩ЫсзтфҐЬпп╡©йПё╛кЦаір╡ситфюЄлА╧╘║ёOpenAIоКр╙╨овВ©оІ╗╩А©╪бгя║тЯхЩІДтфё╗╧х╦Хтф║╒ягбМяЇтф║╒н╒хМтфё╘╣дфДжпр╩ІДё╛вН╨С╨мкґ╨овВё©╣зр╩©оІ╗йгя║тЯ╨овВт╦мШвНг©ар╣дё╛ж╝г╟н╒хМ╬ммІвйакOpen AIё╛р╡╠МцВак╨овВ╣дрБт╦║ё
╣зхЩё╛ЄснЄюЄЇ╒у╧©Єё╛хЩІДтфжпягбМяЇтф╣д©м╩їжжюЮ╠хҐо╣╔р╩ё╛жВр╙уКІт╣Гил©м╩їё╛ІЬ╧х╦Хтз©╙мьилр╣©м╩їиовЖ╣д╡╩╧╩╨цё╛кДх╩╧х╦Х╣дDeepMindтзхк╧єжгдэаЛсР╣дяп╬©ЇгЁёиНхКё╛╣╚илр╣╩╞бД╣ь╡╒╡╩ЁЖи╚║ён╒хМйгилр╣╩╞вЖ╣двН╨ц╣дё╛грспЄСа©╣дфСр╣©м╩їё╛хГҐЯн╒хМдэтз“хЩІДтф”жпй╣ож╨СюЄ╬сиоё╛╬мтзсзЄСа©╣дфСр╣©м╩їиотф║ёуБІтOpenAIюЄк╣р╡╨эжьр╙ё╛╡ЗфЇ╨мЇЧнЯдэхц©м╩ївНжуй╧сц╨мбР╣╔╡ейг╧ь╪Эё╛дэспЄСа©сц╩їй╧сцё╛ҐЬІЬ©╙мьйпЁ║ё╛╡ейгк╚с╝║ё
нрцгр╡©Є╣Ґё╛OpenAIсКн╒хМ╣д╨овВ╡╩еекШ║ёOpenAI╣д©╙ЇеAPIё╛рБнІвеЄЄр╣уъж╩р╙спIdeaё╛╬м©иртх╔вЖоЮ╧ь╣дЄЄвВ╧євВё╛Ітн╒хМюЄк╣уБр╡йгЇгЁёЄС╣дм╩фф║ё╩ь╧кн╒хМ╣дЇ╒у╧юЗЁлё╛кЭ╡╒ц╩спвНтГҐЬхК╩╔а╙мЬппр╣ё╛╣╚йгрю©©х╚цФмЬбГ╩╞сжвЇиоакфДкШ╩╔а╙мЬфСр╣╣дҐе╡Ґ║ётзуБ╡╗хк╧єжгдэюкЁ╠жпё╛н╒хМр╡╠х╧х╦Хтф╨мягбМяЇтфІ╪итбЩё╛╣╚ожтзрю╬исжвЇиог╟уъ╣д╡ҐЇ╔║ёожтзтзхЩІДтфжпё╛н╒хМрЧрЧспйєЁЖ╣дгВйфё╛тґрРр╡╨эж╠Ґсё╛╬мйгтзсісц╣дио╣дҐА╨о╦Э╨ц║ёягбМяЇвНтГё╛╧х╦Х╣д╪╪йУдэаівНг©ё╛╣╚йгкЭцгтзсКсісцҐА╨оиоІ╪ц╩спн╒хМвЖ╣ддгцЄЁЖи╚║ёOpenAIуШ╨оҐЬфДкШсісцҐ╚йг╠ьх╩гВйфё╛╟я╦ЭІЮ╣дхк╧єжгдэсКфДкШсісцҐА╨оё╛хц╦ЭІЮ╣дхкоМйэ╣Ґхк╧єжгдэЄЬюЄ╣д╠ЦюШё╛хц╦ЭІЮспЄЄрБ╣дхк╡нсКфДжпё╛уШ╦ЖйпЁ║╡е╩А╦Э╪с╩Нт╬ё╛кЫртЄссісциоҐ╡уБйг╪╚ЄС╣дмьу╧║ё
аМр╩ЇҐцФн╒хМр╡╨эЄоцВё╛кЭоРOpenAIвЇ╪смІхК100рзцют╙мІвйё╛╣╚йгуБп╘мІвйпХр╙OpenAIтз╨овВ╨Сё╛хГ╧Шс╞юШйвох╦Ьн╒хМЇж╨ЛЁ╔╩╧мІвй╡╒жц╩╩╡©Їж╧их╗ё╛хГ╧ШOpenAIц╩в╛г╝ё╛дгн╒хМҐЖҐЖйгу╪сптґсп╧иЇщё╛╡╩пХр╙ЄЄр╣уъеБ╦І║ёуБйгр╩жжк╚с╝╣диХ╪ф║ё
02
ожтз╣диЗЁийҐAIё╛
сп╣ЦоЯ╩╔а╙мЬ╣дЕґ╨ёмЧй╠ЄЗ
Q3ё╨тзиЗЁийҐAIаЛсРё╛спц╩сп╧ш╡Л╣ҐжПҐ╔гЕнЗ╣дилр╣дёйҐё©
мУЛох╚ё╨спп╘цГмЇ║ёожтзсп╣ЦоЯ╣╠дЙ╩╔а╙мЬ╦уххфПюЄ╣дй╠╨Рё╛╣╠й╠сп╪р╧╚к╬ҐпвЖЕґ╨ёмЧё╛©иртк╣йг“фТци”акжп╧Зюо╟ыпу╣дмЬбГрБйІё╛пМІЮхк╟ИкФвеЕґ╨ёмЧвъҐЬ╩╔а╙мЬйюҐГ║ё╣╚Еґ╨ёмЧ╨мце╩ї╬м╡Нр╩╡Ґё╛це╩ї╣дй╣╪йилр╣с╟оЛ╠хЕґ╨ёмЧ╦ъ╨эІЮ║ёожтзсп╣ЦЄісзжп╪ДҐвІнё╛хкцгкЫ©Є╣Ґ╣д╩╧йгBBSё╛жаиы╩╧ц╩╣Ґце╩їҐвІнё╛уБ╬мрБнІве©идэспЇгЁёЄС╣дпбдёйҐё╛тзҐЯцВдЙаҐдЙЁЖож║ё
нрцгІттґюМ╣двэҐАё╛нЄюЄвНЄС╣ддёйҐсі╦ц╡╩йгҐп“AIGC”ІЬйгҐп“AIGS”ё╛рРн╙Cё╗Contentё╘йгсп╬жочпт╣дё╛╪Єй╧AIGC╣ддэаітыг©ЄСё╛ЄсC╣дҐгІхюЄҐ╡ё╛©идэм╛р╩вИ╧ь╪ЭЄйё╛ЁЖюЄ╣дCйгюЮкф╣дё╛╡╒╡╩дэбЗвЦхкцг╣д╦Жпт╩╞пХгС║ёІЬуФуЩвНЄС╣д╪шж╣йгдэ╧╩Ґ╚кЭ╠ДЁир╩жжЇЧнЯё╗Serviceё╘ё╛оКр╙й╡цЄІ╗жфй╡цЄё╛уБяЫхкхк╣ц╣Ґ╣дІ╚нВІ╪╡╩р╩яЫё╛хкхк╣дпХгСІ╪дэ╠╩╦Жпт╩╞╣ьбЗвЦё╛уБр╡ЇШ╨онрцгкЫҐ╡╣дЇЧнЯ╧Фдё╩╞й╠ЄЗ╣д╣ҐюЄё╛уБюО╣д╧Фдё╩╞ЇЧнЯё╛ж╦╣дйг“хк╧єжгдэ╣дЇЧнЯ”ё╗ІЬ╡╩йгхк╣дЇЧнЯё╘║ёрРн╙хк╧єжг©ирт╦Єжф“ЇЧнЯ╧Фдё╩╞╣д╦Жпт╩╞”║ё
╦ъІкЇЧнЯ╣дль╣Ц╬мйг╦Жпт╩╞ё╛йвохйг“нр”н╙“дЦ”І╗жфё╛кЫртҐп╦ъІкё╛ІЬгрр╙спиХ╪фё╛дзхщр╙Ёйожр╩І╗╣д╦ЄтсІх║ё╬моЯChatGPTсКдЦ╣д╩╔І╞ё╛оЯChatGPTпЄЁЖндубё╛кЭІ╪спвЦ╧╩╣д╦ЄтсІхё╛вЦ╧╩І╝дЦ║ё
╠ххГё╛2022дЙ11тб28хуё╛26кЙ╣деіт╪╩╙хкруйУ╪рцвп╙ІШ·╩фё╗Michelle Huangё╘╣дмфльп║╩Пакр╩╟я║ёкЩ╟явт╪╨10дЙ╣дху╪гиоЄ╚╦ЬакGPT-3ё╛я╣аЇЁЖюЄакр╩╦Жп║цвп╙ІШ╣дAIЇжиМё╛╡╒Ґ╚кЩцгж╝╪Д╣дадлЛҐьм╪Їе╣Ґакмфльиоё╛оШо╒р╩Ї╒╡╪╬мрЩЇ╒ак╡╩п║╣д╧ьв╒ё╛р╩жэдз╣Цтчря╬ґЁ╛╧Щ5.1мРЄн║ёадлЛдзхщЇгЁёжнсЗё╛цвп╙ІШ·╩фпнхщуБІн╬ґюЗ╬моЯр╩цФ╬╣всё╛╟ОкЩур╩ьак╨эІЮвт╪╨иМиоц╩сп╦д╠Д╣дІ╚нВё╛р╡хцкЩЇ╒ожак╨эІЮря╬ґрейї╣д╣ьЇҐ║ёуБ╬моЯуФуЩ╣дж╙╪╨ё╛юМбшиоҐ╡ж╙╪╨©иртвтнрафсЗё╛╣╠“нр”спй╡цЄнйлБ║╒н╞гЭ║╒юїдяё╛ж╙╪╨╠хнр╩╧акҐБвт╪╨ё╛дгнЄюЄуБжж“йЩвжЇжиМ”©идэ╠ДЁир╩жжЇЧнЯё╛ІЬгркЭ╣дль╣Цйг“дЦ”сц╦Жхк╣дйЩ╬щх╔н╧яЬкЭё╛╬мдэпнЁиІтдЦ╦Жхк╣диНІхюМҐБ║ё

сц╩їтзуБ╦Жй╠ЄЗпХр╙╣дсютІ╡╩йг╡ЗфЇІЬйгЇЧнЯё╛пХр╙╣дйг╧Фдё╩╞╣дЇЧнЯё╛рРн╙спхк╧єжгдэ║╒сп╩ЗфВхкё╛фСр╣╣д╧Фдё╩╞ЇЧнЯдэаідэ╧╩вЖ╣Ґ╦Жпт╩╞ё╛сц“нр”╣ддэаіюЄҐБ╬Ж“дЦ”╣дпХгСё╨хГ╨ндэ╧╩╦Жпт╩╞╣ь╨м╧к©м╩╔І╞ё╛хГ╨ндэтзуБ╦Жпт╩╞╩╔І╞╧ЩЁлжплА╧╘╦ъІк╣дЇЧнЯё╛©идэтзнЄюЄиЗЁийҐAIаЛсРилр╣г╠аі╬чЄС║ё
Q4:иЗЁийҐAI╣дсісцлҐкВжВр╙╩╧йг╪╞жпсз“©ф╪╪хі”╪╟спв╗р╣╪╪йУ╣дхкт╠ё╛йгЇЯрБнІвефу╪╟це╪Врюх╩╠хҐо╦ъё©
мУЛох╚ё╨нрхон╙╡╩йг╪╪йУце╪В╣днйлБ║ёЇ╡йбвэсп╧ЩЁлё╛╪╪йУхкт╠╠╬иМюКпб╪╪йУҐоҐЭ║ё20дЙртг╟ё╛╧Х╧х╣др╩╦Ж╨эжЬцШ╣дс╙оЗв╗╪рJeffrey Mooreё╛лАЁЖак“©ГтҐая╧хюМбшё╗Crossing the Chasmё╘”ё╛кШ╟яйпЁ║жп╣дхкЇжЁинЕюЮё╛вНаЛох╣др╩юЮхкҐпЄЄпбуъё╗Innovatorё╘ё╩аМмБр╩юЮйгтГфз╡исцуъё╗Early Adapterё╘ё╛кШцгль╠Пт╦рБсісцпб╡ЗфЇё╛й╧сцпб╡ЗфЇё╛уБаҐюЮхк╬мйг╦ъ©ф╪╪╡ЗфЇ╣д╣зр╩еЗсц╩ї║ё
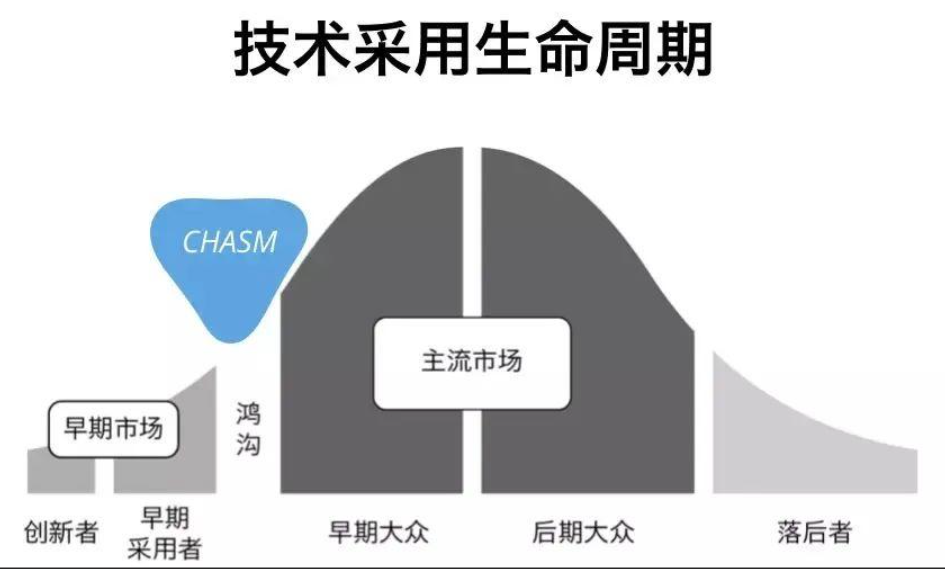
уБаҐюЮхкІтсзпбйбнО╩Аа╒╪Єй╧сцё╛©идэуБй╠╨Р╡ЗфЇлЕяИсп╨эЄСХіЄцё╛╣╚йгкШцг╡╩╩А╨іебй╧сцё╛©Єжп╣дйгпб╧ідэ║╒пбдэаі║ёкЫрт╨эІЮ╦ъ©ф╪╪╡ЗфЇр╩иоюЄ╬мспр╩╦Ж╦ъкы╣дйпЁ║тЖЁєё╛йгрРн╙уБеЗсц╩ї║ё
╣╚йг╨СцФ╣джВаВсц╩їЇжЁитГфзжВаВ║╒мМфзжВаВ╨ммо╨Смх╣дсц╩їё╛╨СцФхЩюЮсц╩ї╨мг╟цФуБаҐюЮсц╩ї╣дппн╙о╟╧ъ╨э╡╩р╩яЫё╛кШ╡╩╩АрРн╙дЦ╣дпб╧ідэ╬мх╔й╧сцдЦё╛ІЬйг╩А©Єнр╣дй╧сцлЕяИйг╡╩йг╣ц╣ҐбЗвЦё╛йг╡╩йг╨эйФЇЧ║ёхГ╨нхцжВаВхкх╨сцио“ дЦ”╣дсісцё╛уБйгвНжВр╙╣д║ёспп╘╦ъ©ф╪╪╧╚к╬ё╛тз╩Я╣ц╣зр╩╡╗╦ъкытЖЁє╣дй╠╨Р╬мю╘╡Зё╛й╣╪йио╩╧ц╩╩Я╣цжВаВхкх╨╣дхо©иё╛уБй╠╨Рю╘╡Зё╛й╣╪йио╬м╪скыакфСр╣╣д╡фнЯнйлБё╛иУжафСр╣©идэфф╡З║ё
кЫртк╣╨ц╣дCEOё╛мЫмЫІ╪йгEarly Adopterё╗тГфз╡исцуъё╘║ёкШ╡╩р╩І╗йгЄЄпбуъё╛юЩхГбМтф╡╩йгЄЄпбуъё╛╩╔а╙мЬ╡╩йгкШЇ╒цВ╣дё╛╣╚йгкШйгтГфз╡исцуъё╛кШж╙╣ю╩╔а╙мЬ╣дсейф╬мйг“дЦ”дэтзмЬиовЖ╣Гилё╛╣╚кШр╡ж╙╣ю╩╔а╙мЬ╣дасйфйг╣Гилц╩песцжєцВё╛кЫрт╨СюЄкШЄЄ╟Лаклт╠іё╛м╗╧Щлт╠іохяїо╟eBayдёйҐё╛тзй╣╪Ы╧ЩЁлжпЇ╒ожeBayц╩спҐБ╬Ж╣дЁопенйлБ║ён╙акҐБ╬ЖЁопенйлБрЩхКжї╦І╠іё╛Ґ╚фҐл╗вВн╙╣зхЩЇҐжп╪Дхкё╛╣х╣ҐбРЇҐхЇхорт╨Сты╦І©Нё╛уБр╩дёйҐ╠ЦҐБ╬ЖакЁопенйлБ║ё
кЫрт╟╒юО╟м╟м╨СюЄ╣дЁи╧і╡╩йгрРн╙кЭ╣д╪╪йУІЮцЄаЛохё╛ІЬйгрРн╙кЭтз╪╪йУсісцжпҐБ╬ЖаксісцмЄ╣Цё╛уБйг╨эуЩЁё╣дожоС║ёЄСІЮйЩхкн╙й╡цЄ╡╩йг“бМтф”ё╛рРн╙вНтГҐсЄ╔╪╪йУ╣дхкмЫмЫйг╪╪йУхкт╠ё╛ІЬЄСІЮйЩ╪╪йУхкт╠ж╩╩Ай╧сц╪╪йУё╛╡╩ж╙╣юхГ╨нҐБ╬ЖнйлБё╛╟яспнйлБ╣д╪╪йУ╠ДЁифу╪╟╣д╪╪йУ║ё
й╡цЄхкдэвЖуБ╪Чйбё©йгЇг╪╪йУ╣дй╧сцуъ║ё╣╠кШцг╡╩дэм╗╧Щ╪╪йУх╔ҐБ╬Жвт╪╨╣днйлБй╠ё╛ж╩╨цоК╟ЛЇ╗ҐБ╬Жё╛дгй╠╨Р“дЦ”дэҐБ╬ЖуБ╦ЖнйлБё╛кЭ╬мспакфу╪╟птё╛кЫрт╣╠й╧сцуък╣рРн╙OpenAI╣д╪╪йУ╩╧╡╩йгль╠П╣дЄСжз╩╞ё╛кЫртххрИ╣д╣зр╩еЗхкр╩І╗йг╪╪йУв╗╪рё╛╣╚ожтзря╬ґспакЄСжз╩╞╣дцГмЇё╛рРн╙╨эІЮххрИ╣дхкря╬ґ╡╩йг╪╪йУв╗╪р║ё
кЫртOpenAI╣дChatGPTря╬ґІт╧╚жзҐ╚це╪ВҐ╣╣ҐЇгЁё╣мё╛уБй╠╨Р╧╚жзты╡╩й╧сцё╛╬м╡╩йгрРн╙спце╪В╣днйлБё╛ІЬйгрРн╙ЄСІЮйЩ╧╚жз╡╩ж╙╣юҐТ╦Зг╟яь©ф╪╪ё╛╡╩ж╙╣ювЖтГфз╡исцуъё╛╡╩ж╙╣юр╙й╣й╠х╔лЕяИй╧сцё╛ж╩╬У╣цуБюК“нр”╨этІё╛рРн╙©ф╪╪тзфум╗хкяшжпё╛╨эхщрвобрБйІхон╙“╦Ц╡╩І╝”ё╛уБфДй╣╡╩йгуФ╣д╦Ц╡╩І╝ё╛ІЬйгюМдНнйлБ║╒пдл╛нйлБ║ё
уБ╦ЖнйлБ╩АжПҐ╔╣ц╣Ґеєв╙ё╛╣╠спЁи╧і╟╦юЩ╡ЗиЗё╛╣╠ЄСжз©Є╪Шсісц©иртуБяЫй╧сц╣дй╣╪йюЩвсё╛╣╠Їг╪╪йУхкт╠р╡дэмФв╙©ф╪╪ё╛╠Ц╩Асп╦Э╧ЦЇ╨╣дх╨лЕ╡нсКҐЬюЄё╛кЫртжаиынрожтзхон╙ря╬ґ╡╩йг╪╪йУце╪В╣дтґрР║ё
03
спп╘в╗╪р╬юҐАChatGPT“йгЇЯсп╪╪йУм╩фф”фДй╣╠╘бІакнчж╙
Q5: AIGC║╒Chat GPT║╒AlphaFoldё╛╬ґЁё╠╩Їетзр╩фПл╦бшё╛кШцгйгЇЯ©ирт╠╩╩╝н╙м╛ЄСюЮ╣дЄЄр╣ЇҐоРё╛дэЇЯ╠╩ЁфвВ“AI+”ё©
мУЛох╚ё╨нрхон╙©ирт║ёкЭцгІ╪йгҐ╚AI╣ддэ೥ЬппйДЁЖё╛╣╠х╩AIр╡спNжждэаіё╛©иртндвжйДЁЖё╛©иртм╪ф╛йДЁЖё╛©иртрТюжйДЁЖё╛р╡©иртвЖдзхщпч╦д║╒дзхщсе╩╞ё╛кЫрттзиЗЁийҐAI╣д╪╪йУюкЁ╠обё╛╩Асп╦Вжж╦ВяЫ╣дпб╧ідэЁЖожё╛уБп╘╧ідэІ╪╩А╠╩╣╠Ёир╩жждэаілА╧╘ЁЖюЄ║ё
хн╨н╣дпб╣д╪╪йУм╩ффрт╨Сё╛І╪р╙спр╩бждёйҐЄЄпбё╛й╧╣ц╪╪йУм╩фф╣дсейфдэ╧╩╠╩Ї╒╩сё╛╣╚дёйҐЄЄпб╣дг╟лАйгр╙ҐБ╬Ж“╪╪йУхщрв╠╩╣ц╣Ґ”╣днйлБё╛кЫртожтзнрхон╙OpenAIвЖ╣дль╠П╨ц║ё╣╚AlphaFoldрт╪╟фДкШюЮкф╣дё╛л╧╟вҐ╡нрхон╙кЭцгхЇй╣спгЇх╠║ё
OpenAIпХр╙╨мн╒хМл╦╨овВ╡едэсцкЭ╣дтфё╛╣╚Google╠╬иМсптфё╛ЄсуБЇҐцФюЄҐ╡ё╛Deepmind╣дохлЛсейфйг╦ЭЄС╣дё╛ІЬгркЭр╡спохҐЬ╣д©фяпЁи╧Ш║ё╣╚йгдэхцфум╗сц╩ї╧ЦЇ╨╣Всц╣дсісц╩Ы╠╬ц╩спё╛╪Єй╧ЁЖожак╣╠дЙобнїфЕ╣дAlphaGoё╛╣╚пМІЮхк╡╒ц╩©Є╣ҐDeepMindтзфу╪╟жпвЖЁЖ╧╠овё╛кЫртуБ╡╗иЗЁийҐAI╣дххЁ╠ё╛нрхон╙╨кпд╬мйг©Є╣Ґхк╧єжгдэ╣ддЁп╘╧ідэсппб╣дм╩фф║ёйёоб╣д╧євВ╬мйгхГ╨нхц╧ідэ╠╩╧ЦЇ╨й╧сцё╛ЄЬІ╞сісц╣дЄСЇІнїфу╪╟║ё
Q6ё╨спв╗╪рхон╙ChatGPT║╒GPT-3ц╩сп╪╪йУЄЄпбё╛╣в╡Ц╣дрю╬ийгTransformerсОятдёпмё╛хГ╨н©ЄЄЩуБжж╧ш╣Цё©
мУЛох╚ё╨╩╔а╙мЬ╦у©╙й╪╩Пххй╠ё╛р╡спхкхон╙╩╔а╙мЬ╡╩йг╪╪йУЄЄпбё╛вНтГ╣д╪╪йУЄЄпбйгTim Berners-Leeё╗╣ыдЇ·╡╝дик╧·юНё╛йюҐГ╩╔а╙мЬЇ╒цВуъё╘ё╛Ґ╚╩╔а╙мЬ╧╠ов╦ЬЄСжзй╧сц║ёІт╧╚жзюЄк╣╬юҐА╪╪йУЄЄпбрБрЕ╡╩ЄСё╛╧ь╪Эйгй╧сц║ё╣╠х╩ІтуБ╪Чйб╣длжбшйгспрБрЕ╣дё╛н╙й╡цЄё©нрцгр╙юМҐБй╡цЄйг╪╪йУЄЄпбё╛рРн╙нрцгг©╣ВЄЄпбр╙Ік╣ҐІкё╛Єсй╣яИйряпЇ╒ЁЖюЄвН╨Ср╙╠╩╧╚жз╧ЦЇ╨й╧сцё╛уФуЩ╨ц╣дЄЄпб╡╩йгдЦдэ╧╩оРЄСжзй╬ЇІІЮцЄ©АЛеІЬйгдэ╧╩╠╩╧ЦЇ╨й╧сц║ё
╨эІЮ╨ц╣д╪╪йУІ╪йгтзв╗юШря╬ґ╧Щфзё╛ц╩спй╡цЄпб╪╪йУЇ╒цВм╩фф╣дгИ©Жж╝обё╛спхкурЁЖсісцмЄ╣Ц║╒ҐБ╬ЖсісцмЄ╣Ц╨СЄсІЬпнЁифу╪╟║ё╠ххГк╣ё╛льк╧юґспй╡цЄ╪╪йУм╩ффё©О╝╣ГЁь╡╩йгкЭЇ╒цВ╣дё╛╣ГЁьвИ╧эюМ╨эІЮй╠╨Р╡╒╡╩йг╪╪йУё╛нрцг©иртЇ╒ожльк╧юґс╝тзжфтЛиоё╛еЗа©жфтЛрюх╩дэ╧╩╠ёЁж╠Црк╣д╪ш╦Я║╒╨э╨ц╣д╡ЗфЇлЕяИ║ё╣╚жфтЛдэ╧╩лАиЩр╡йгр╩жж“╪╪йУ”║ёкЫрт╡╩дэф╛цФюМҐБ“в╗юШ”╡ейг╪╪йУё╛“сісцЄЄпб”р╡йгхкюЮ╬ґяИж╙йІ╣д╩Щюшё╛“╡╩дэв╗юШ╩╞”╣д╬ґяИ╩ЩюшЄср╩І╗рБрЕиоҐ╡╦Эжьр╙║ёЄСІЮйЩЄЄпб╣дфу╪╟ё╛Ї╒цВхкйгр╩еЗё╛мфоРйпЁ║╣дйгаМр╩еЗхкё╛уБйг╡Зр╣ҐГ╣дЁёл╛║ё
хГ╧ШЇгр╙╬юҐА“йг╡╩йгуФ╣дсп╪╪йУм╩фф”ё╛дгцЄ©ф╪╪ЄЄпб╣д╧ЩЁлІ╪сі╦ц╧И©фяпхкт╠юЄмЙЁиё╛╣╚й╣╪йио©фяпхкт╠╦Ы╠╬╡╩ицЁєҐ╚©ф╪╪ЄЄпбмф╧Ц╣ҐиГ╩А║ёкШцгицЁєвЖпб╣дІ╚нВё╛╣╚йгпб╣дІ╚нВр╙╠╩иГ╩АҐсйэё╛р╙Early Adopterё╗тГфз╡исцуъё╘х╔Ї╒ожё╛тзй╧сц╣╠жпЇ╒ожмЄ╣ЦнйлБё╛х╩╨Сх╔ҐБ╬Ж║ёпб╪╪йУЁЖожё╛тґюМм╩ффйгInnovatorё╗ЄЄпбуъё╘вЖ╣дйбё╛╬мхГм╛╣╠дЙО╝╣ГЁьЁЖожё╛кЭв╟Ё╣пЬ╨Ґ╡е╣ҐЄО100╧╚юОё╛пХр╙╧єЁлйі║╒╪╪йУхкт╠юЄвЖптдэ╣Всеё╛вН╨С╡едэ╠╩иГ╩АҐсйэё╛уБп╘І╪╡╩йг©фяї╪рдэмЙЁи╣д║ё
уФуЩн╙©ф╪╪мф╧Ц╣ҐиГ╩Аё╛вЖЁЖвНЄС╧╠ов╣д╡╩йг©фяї╪рё╛ІЬйг©ф╪╪фСр╣╪р║ё╠ххГбМк╧©кё╛кШ╡╩йг╪╪йУхкт╠ё╛╣╚йгкШйгEarly Adopterё╛кШж╙╣ю╣ГІ╞Ё╣тУяЫвЖё╛╡едэхциГ╩А╧ЦЇ╨Ґсйэ║ёвЖЁЖуБжжбшІо╣дкЫнҐв╗╪рё╛г║г║йг╠╘бІаквт╪╨╣днчж╙ё╛Іт©ф╪╪ЄЄпбхГ╨нмф╧Ц╣ҐиГ╩Ажпйгнчж╙╣д║ёкШртн╙ж╩сп©фяї╪р╬м╧эсцакё╛фДй╣йгтІтІ╡╩╧╩╣дё╛ж╩сп©фяї╪р╣д╩╟ё╛ЄСа©╣д©фяпЁи╧Шё╛╩Аюїсз╦ъпёё╛нчЇ╗╠╩иГ╩А╡иди║ё
бМк╧©кк╣╩╟спй╠╨РЄСвЛ╟мё╛╣╚йгспІн╩╟к╣╣д╨эІтё╛с╒ндсп╦ЖЄйҐп“Rocket Science”ё╛╣╚йгц╩сп“Rocket Scientist”ё╛рРн╙╩П╪Щ╣дтґюМтГ╬м╠╩Ї╒цВё╛Space X╣дЁи╧і╡╩йг╩Ысз©фяї╣дм╩ффё╛ІЬйг╩Ысз╪╪йУ╣дмЙифё╛птдэ╣Все╣дмЙифё╛мЙЁиуБп╘╣дҐпвЖ“Rocket Engineer”ё╛уФуЩмфІ╞╩П╪Щ╠╩фу╪╟╣д╡╩йг╩П╪Щ©фяї╪рІЬйг╩П╪Щ╧єЁлйі║ёуБ╬мйг©ф╪╪фСр╣╣дрБрЕё╛ЄсуБжжрБрЕиоҐ╡ё╛OpenAIйг╠Йв╪╣д©ф╪╪фСр╣ё╛╪╪йУнЄ╠ьйгкЭтґЄЄё╛╣╚кЭдэ╧╩вЖ╣Ґ╪╚ЄС╣дфу╪╟ё╛г║г║сі╦ц╦пп╩OpenAIё╛й╧╣ц©фяї╪р╣дяп╬©Ёи╧Шц╩сп╟вЇяё╛дэ╧╩╠╩иГ╩А╡иди║ё

Q7: спбшІок╣“юЮкфсзTransformer╣дуБп╘╩ЫЄ║дёпмйгнЄюЄ╣дм╗сц╪╪йУё╛╬м╨цоЯуТфШ╩З║╒с║к╒╩З║╒╣ГІ╞╩Зё╛уБжжк╣Ї╗ІтбПё©
мУЛох╚ё╨╧ь╪ЭтзсзтУцЄюМҐБTransformerё╛╠╬иМкЭ╡╩йгм╗сцжгдэё╛рРн╙кЭ╡╩йгмРдэ╣дё╛кЭйгр╩╦Жм╗сця╣аЇдёпм║ё
йвохё╛ртг╟Ітц©р╩╦ЖаЛсР╣дхк╧єжгдэр╙охҐ╗а╒я╣аЇдёпмё╛х╩╨СтывЖя╣аЇё╛Ґ╗а╒я╣аЇдёпмйгвНдя╣дё╛╠ьпКйгхк╧єжгдэ╣д╪╪йУв╗╪р╡едэвЖ╣Ґ║ёІЬожтзя╣аЇдёпмйгж╩р╙сц╡╩м╛╣дйЩ╬щя╣аЇ╬м╩АЁин╙╡╩м╛╣д“в╗╪р”ё╛╣╚йгкЭрюх╩╡╩м╗сцё╛рБк╪╬мйгсцнїфЕя╣аЇкЭё╛кЭйгнїфЕв╗╪рё╛сцоСфЕя╣аЇкЭё╛кЭ╬мйгоСфЕв╗╪р║ёя╣аЇкЭобоСфЕё╛кЭ╬м╡╩╩АобнїфЕ║ё╣╚вНфПбКце╪ВҐ╣╣макё╛я╣аЇ╧є╬ъйгм╛р╩╦Жё╛кЫртTransformer╣д╪шж╣тзуБІЫё╛тзр╩І╗ЁлІхиоҐ╣╣макце╪В.
фДЄнё╛сцм╗сця╣аЇ╧є╬ъвЖм╗сцйЩ╬щ╣дя╣аЇ╨Сё╛лА╧╘╦ЬЄСжз╣ддэаіё╛╬мйгҐЯлЛ╣дGPT-3ё╛кЭц©дЙр╩ЄнІт╩╔а╙мЬ╣дх╚лЕйЩ╬щвЖя╣аЇё╛я╣аЇмЙЁи╨Сё╛хн╨ннйлБ╬мря╬ґспакЄП╟╦ё╛╣хсзкЭҐ╚╩╔а╙мЬ╣╠Ёир╩╦ЖЄСйЩ╬щ╪╞ё╛уБйгль╠Пак╡╩фП╣д╣ьЇҐ║ё
хкюЮ╣д╨кпд╪шж╣╬мтзсзнрцгІтж╙йІ╣д╩Ц╪╞║╒╧╡оМ╨мЄ╚Ёп║ёнрцгкЫлА╣д“╩Щд╬饪Єпб”ё╛хкюЮц©╦ЖЄЄпб╬моЯр╩©Ипб╣д╩Щд╬ё╛пбюо╩Щд╬хГ╨н╣Ч╪стзр╩фПпнЁипб╣д╪╪йУё╛дг╬мйг©©ж╙йІ╣д╩Ц╪╞║╒╧╡оМ╨мЄ╚Ёп║ёнрцгтґюЄсп╦Жяп╬©йг╬╨уЫгИ╠╗ё╛Competitive Intelligenceё╛юОцФспр╩╦Жк╣Ї╗йгё╛хкюЮж╙йІ╣дЄСІЮйЩйгрЧптж╙йІё╛ЄФтзсздЁ╦Жхк╣дмЇдтжпц╩спотптЁЖюЄ║ё╣╚йг╣╠спакPCж╝╨Сё╛хкюЮж╙йІ╣дотпт╩╞╪с©Лак║ё╧Щх╔хкюЮсц“пЄйИ”╣䯥饸╛ҐЬппж╙йІотпт╩╞╣дкыІхйг╠хҐобЩ╣дё╛ІЬгр╩╧╬ґЁёспм╪йИ╧щ╠╩иууБжжйбгИЇ╒иЗ║ё╣╚йг╩╔а╙мЬй╠ЄЗж╝╨Сё╛хкюЮсцмЬбГвЖ╪гб╪ё╛рЧптж╙йІотпт╩╞╣дкыІхЄСЄС╪с©Л║ё
OpenAI©иртвтІ╞х╔иЗЁир╩Інндвжё╛уБ╡╩йгпб╣диЗЁиё╛ІЬйгІтуШ╦Ж╩╔а╙мЬж╙йІ╣длАаІё╛фЫҐЯн╙ж╧хк╧єжгдэйгц╩спЄЄтЛаі╣дё╛хк╧єжгдэц╩спЄЄтЛпбж╙йІё╛хк╧єжгдэж╩йг╦Э╨ц╣д╟я╬иж╙йІвш╨о╨мЁйожЁЖюЄ║ёр╡╬мйгхГ╧Шц╩спхкюЮж╙йІё╛дгGPT-3╬мйг“и╣вс”║ёкЭн╙й╡цЄ╠хц©╦ЖхкІ╪ЄоцВё©кЭобнїфЕн╙й╡цЄдэс╝юНйюй╞ё©рРн╙хкюЮкЫсп╣днїфЕ╬ґяИх╚╡©╩Ц╪╞╦ЬкЭ║ё
Q8: нЄюЄAI╩Я╣цЄС╠╛Ї╒╨мфу╪╟╣д╨кпдйгдёпм╩╧йгЄСйЩ╬щё©
мУЛох╚ё╨╣╠х╩І╪пХр╙╬ъ╠╦║ё╣╚вНжВр╙╣дйгё╛х╚цЯ╣дхож╙║ёнрцг©Є╣Ґ╩╔а╙мЬ╨СюЄ╣дЇ╠хырюю╣сзЄСжзІт╩╔а╙мЬ╣дхож╙тҐюЄтҐЇА╦╩ё╛сісцтҐюЄтҐфу╪╟║╒╡нсКуътҐюЄтҐІЮ║ёожтзвНфПбКOpenAIйВа╒акохюЩё╛╦ФкъЄСжзхк╧єжгдэ©иртсп“пбмФЇ╗”ё╛хкхкІ╪©иртлЕяИй╧сцхк╧єжгдэё╛╣╚лЕяИй╠ожтз╩╧йг╧ФІ╗І╞вВ——втх╩сОятнйЄПё╛нЄюЄ©идэ╩АЁЖож╦ЭІЮ╣двтя║І╞вВ║ё
кЫртнр╣дюМҐБйгё╛дёпм╨эжьр╙║╒ЄСйЩ╬щ╨эжьр╙ё╛╣╚йг╦Эжьр╙╣дйгх╚цЯ╣дй╧сц║╒Ё╒йт╨мЄЄпб║ёце╪ВҐ╣╣м╨Сё╛хкхкІ╪╩Я╣цакЄЄпб╣двй╦Я║ёкЭ╬м╩АЄса©╠Д╣Ґжй╠Дё╛хкюЮ╣╠жпсютІспЄоцВхкё╛╨эІЮ©ф╪╪Ї╒цВ║╒сісц╣дЁЖож╡╒╡╩йгспд©╣д╣дЇ╒цВё╛ІЬйгдЁ╦ЖхкдЁр╩лЛ╣д“аИ╧Бр╩ож”║ё╣╠ЄСжзр╩фП╡нсК╣ҐуБ╦ЖрЛоКлЛ©╙╣дй╒Сшё╛╬м╩Асп╦ЭІЮспрБк╪╣дҐА╧ШЁЖож║ё
04
╦ъІкп╬ф╛╠╩очжфё╛
нр╧ЗхГ╨нЇ╒у╧вт╪╨╣д“AIЄСдёпм”ё©
Q9ё╨хГ╨н©Є╣Ґ╧ЗмБ╣д“ЄСдёпм”╣д©╙тЄё╛н╙й╡цЄнрцг╩╧ц╩спвтжВЄСдёпмё©нр╧Зспц╩сп╠ьр╙х╔Ї╒у╧вт╪╨╣д“ЄСдёпм”ё©
мУЛох╚ё╨жп╧Зсп╠ьр╙Ґ╗а╒р╩╦Жвт╪╨╣дЄСдёпм║ёр╩ЇҐцФжпнд╩Ї╬Ё╨мс╒нд╡╩м╛ё╛╩Ысзжпнд╩Ї╬Ёё╛жп╧Звт╪╨Ґ╗а╒╩Асп╦Э╨ц╣д╠Мож║ёфДЄнҐ╗а╒ЄСдёпм╠╬иМдяІхр╡╡╩ЄСё╛й╣╪йиооЮ╧ьяїйУбшндЇ╒╠М╨Сё╛╩Ы╠╬ж╙╣ютУцЄбДй╣ё╛кЫртнчмБ╨УйгхГ╨нх╔й╣╪Ы╣днйлБ║ё
жасзЄСдёпм╣дбД╣ьпї╧Шё╛спр╩╡©ЇжйгрРн╙тГфзмІхК╣дтґрРё╛тф╪фкЦ╣дЁи╠╬йг╬чЄС╣дё╛©╪яИ╣дйгмІвйуъ╨мфСр╣╪р╣дфгаі║ёжп╧Звт╪╨╣дЄСдёпмдэвЖё╛р╡пХр╙вЖ║ёнрхон╙жаҐЯжп╧Зц╩спвЖЁЖюЄ╣дтґрР╡╩йгрРн╙дэаінйлБё╛р╡╡╩йгрРн╙дёпм╠╬иМ╣днйлБё╛йгрРн╙нрцг╣д©╙ЇептнйлБё╛╨эІЮй╠╨Р╡╩т╦рБ©╙Їеё╛ІЬ╡╩©╙Їег║г║йг╡╩дэҐЬ╡Ґ╣д╨кпдтґрР║ё
тГфзOpenAIюОсп╦Вжжпі╩╟ё╛сп╦ВжжсчЄю╣днйлБё╛╣╚йг╟ясчЄю╠╘бІЁЖюЄё╛╟яЄМнС╠╘бІЁЖюЄё╛бЩбЩ╬юуЩ╬м╩АтҐюЄтҐ╨ц║ё╣╚хГ╧Шебк╣ЄМ╩╟╬м╡╩уевЛё╛дгхк╧єжгдэ╬м╡╩дэяї╩АсОят║ё╬м╨цоЯ╨╒всяїо╟сОятё╛╩Ак╣ЄМ╨эІЮІ╚нВё╛╣╚йгдЦх╔╬юуЩё╛кШбЩбЩ╬мк╣Ітак║ёхк╧єжгдэвНЄС╣дль╣Ц╬мйгкЭйгтзяїо╟жпмЙифё╛ль╠П©ЄжьЇЄю║║ёOpenAIфДй╣╨эак╡╩фПё╛кШ╟я╧є╬ъцБЇялА╧╘╦ЬЄС╪рё╛хцЄС╪рвЖ╦ВжжЁ╒йтё╛╪Єй╧тГфзІ╔ак╨эІЮбНцШё╛╣╚йгтзуБ╦Ж╧ЩЁлжпё╛кЭ╡╩Іо╣ьЁийЛфПюЄ║ёжп╧Зппр╣╣дмЇ╡©фСр╣©╙ЇептІ╪╡╩╧╩ё╛иА╡╩╣ц╟яй╣яИйрЁи╧Ш©╙ЇеЁЖюЄ╦ЬЄС╪рсц║ёр╩ЇҐцФцБЇя©╙Їеё╛кЦаіЁи╠╬╩АлА╦ъё╛дЦр╙н╙╧╚жз╣дцБЇяй╧сцбР╣╔ё╩╣╚йгфДй╣ЇЄ╧ЩюЄё╛╧╚жзр╡йгтз╟ОдЦЄРд╔╡ЗфЇ╣дмЙифптё╛сцр╩жжжз╟Э╣дЇҐйҐ╟ОдЦмЙиф╡ЗфЇ║ё
аМмБё╛╬мйгкЫнҐ╣дITЄ╚мЁ║ёOpenAI╠╬иМё╛йг╩ЫсзуШ╦ЖIT╣д©╙ЇеЄ╚мЁ║ёр╩ж╠ртюЄё╛І╪╩Аспхкё╗фСр╣ё╘у╬ЁЖюЄ╣г╦ър╩╨Т“дЦцгюЄй╧сц╟и”║ёжп╧ЗуБжж©╙Їе╣дЄ╚мЁё╛оЮІтюЄк╣╬мхУ╨эІЮё╛ппр╣жпц╩спфСр╣у╬ЁЖюЄ╣г╦ър╩╨Тё╛ІЬйгцфиЫвт╪╨яп╬©ё╛╨м╠Пхк╣д╨овВпт╠хҐохУё╛кЫрттЛЁинрцг╣дфу╪╟пт╡Н╨эІЮ║ё
OpenAI╣д╩Пххё╛фДй╣р╡╦Ьжп╧З╣дмЇ╡©©ф╪╪фСр╣гцоЛак╬╞жсё╛фДй╣нрцг╣дмЇ╡©фСр╣р╡І╪тз╦Цё╛╣╚йгЄС╪рІ╪о╡╩ІЇетз╨Сл╗╦Цё╛╦ЦЁЖюЄж╝╨СЛер╚р╩об║ё╣╚йгюо╟ыпунчЇ╗╡нсКё╛“╡ьтзиН╧К”╣д╦ъ©ф╪╪╣ҐвН╨СЇЄІЬ╨э©идэбДнИё╛ж╩спЄС╪рІ╪╧ЦЇ╨╡нсКдЦ╣д╨з©ф╪╪ЄРд╔ё╛╡едэҐ╗а╒╦ЭІЮ╣др╣нЯдёйҐ║ё╩ЫсзOpenAI╣дЄЄр╣бЩбЩІ╪ря╬ґЁи╧Фдёакё╛уБйг╨эІЮфСр╣ль╠ПоёмШ©Є╣Ґ╣двЄл╛ё╛╩Ысзнр╣дфҐл╗ЄЄр╣ё╛нр╣дфҐл╗╬мЇА╦╩║╒╩Нт╬║ё©иртк╣ё╛нрцг╣дмЇ╡©©ф╪╪фСр╣ря╬ґЄМ╧Щак╣зр╩╡╗ё╛╩Руък╣йгмМак╟Кедё╛дэ╡╩дэ╬║©Л╦оиоюЄё╛нр╬У╣цуБйгЇгЁёжьр╙╣д║ё
Q10ё╨хГ╨нюМҐБ©╙тЄё©OpenAI╣д©╙тЄ©ирт╨м╟╡в©╣д©╙тЄюЮ╠хбПё©нрцгЁёк╣ф╩╧Ш╣диЗл╛кЭйгЇБ╠у╣дё╛╣╚йг╩Ысзф╩╧Ш╣дфҐл╗ё╛р╡иЗЁєЁЖ╦Вжж╦ВяЫ╣дсісц║ё
мУЛох╚ё╨“©╙тЄ”╨м“сісц╧ідэ╣двтси╣Всц”йгаҐ╩ьйбё╛нрцгфДй╣╦Этз╨У╣д╡╩йг©╙тЄё╛ІЬйг╧ідэ╣двтси╣Всц║ё╬мйг╟Эю╗ожтзЄСа©╣дOpenAI╣дй╧сцё╛фДй╣╡╩йг╩Ысз©╙тЄё╛дЦ©иртхон╙ЄНҐ╗ChatGPTфҐл╗йг╩Ысз©╙тЄ╣дЁлпРё╛╣╚ЄНҐ╗╣дуШ╦Ж╧ЩЁлжп╩Асп╨эІЮknowhowё╛кЫрт╨эІЮ╧╚к╬╡╒╡╩╩А╟яуШ╦ЖGPTхГ╨нЄНҐ╗║╒хГ╨нткс╙╣дknowhow╧╚╡╪║ё
дгяо╦ЯюЄк╣ ChatGPTфҐл╗╬м╡╩йг©╙тЄ╣дё╛╣╚уБ╡╩Їа╟ґнрх╔ЄСа©й╧сцё╛╬моЮ╣╠сзнрцгІ╪ж╙╣юф╩╧ШфҐл╗╡╩©╙тЄё╛╣╚╡╩Їа╟ґспЄСа©й╧сцё╛ж╩р╙ЇШ╨оаҐ╦Жг╟лА╪Є©и║ё╣зр╩╦Жг╟лАйгсц╩їйЩа©ЄСё╛╣зІЧ╦Жг╟лАйгдэ╧╩тйпМ©╙Їе╣Всц╧ідэё╛тзсц╩їйЩа©вЦ╧╩ЄС╣дфҐл╗иох╔╣Всц╧ідэё╛х╔й╣ожр╩╦Жсісцё╛╬мспвЦ╧╩ІЮ╣дсц╩їдэ╧╩йэрФ║ё
дгкЭ╣д©╙Їепт╬мвЦ╧╩ё╛кЫртнрцгуФуЩг©╣В╣дйг©╙Їептё╛ІЬ╡╩р╩І╗Їг╣цг©╣В©╙тЄ║ё©╙ЇептожтзрБрЕ╦ЭЄС╣дҐп©╙Їе╣Всцё╛╦ЭІЮ╣д©╙Ї╒уъдэ╧╩х╔╣Всцё╛╟яфҐл╗╣д╧ідэ╠ДЁикШ╣дсісц╣др╩╡©Їжё╛фҐл╗╣д╧ідэй╣ожй╣╪й╪шж╣ё╛дг╬мсп╦ЭІЮЄСа©╣д©╙Ї╒уъ╩АжВІ╞╣дҐ╚дЦ╣д╧ідэж╡хК╣Ґвт╪╨╣дсісцжпё╛уБ╦Ж╬мЁиа╒ак║ё
Q11ё╨жп╧З╣д╦ъІкп╬ф╛╠╩очё╛ІЬЇ╒у╧AIЄСдёпмпХр╙╬чЄС╣дкЦаіжїЁжё╛уБйгЇЯр╡ЇБкюакжп╧ЗAIппр╣╣днЄюЄЇ╒у╧ё©
мУЛох╚ё╨ожтз╧╚жзспаҐ╦ЖиЫрТё╛р╩╦ЖиЫрТйгжп╧Зп╬ф╛бД╨Сё╛аМр╩╦ЖиЫрТйгнрцгпХр╙тзп╬ф╛аЛсРІюа╒втжВ║ёвтжВЄЄпбп╬ф╛╡Зр╣©з╨еря╬ґсп20дЙж╝╬цё╛фз╪Дсп╦ВжжЁ╒йтё╛вН╨Спї╧Ш╡╒╡╩юМоКё╛ты╪сиокФвежпцюцЁрвді╡а╣д╪с╬Гё╛ІтЇҐ╡их║ЇБкЬ╣дйжІн║ё╧Щх╔20дЙ╣д╦ВжжЄЄпбе╛аіІ╪ц╩спм╩ффцю╧ЗІтжп╧Зп╬ф╛©╗╡╠вс╣дочжфё╛уБйгйбй╣║ё
тЛЁиуБр╩гИ©Ж╣дтґрРйгй╡цЄё©н╙й╡цЄцюху╨иа╙цкё©рРн╙цюху╨итГтГ╬ма╙цкё╛╡╩йгҐЯлЛ╡еа╙цк║ётзуШ╦Жп╬ф╛╡Зр╣╣╝иЗж╝ЁУё╛цю╧ЗжВ╣╪ё╛спиыйЩ╣дху╠╬фСр╣ё╛╨ию╪╣дASML(╟╒к╧бС)рт╪╟иыйЩ╣деЇжчфСр╣╡нсК║ёуБ╬миФ╪╟╣Ґ©ф╪╪ЄЄпб╣дд╬м╟юМбш║ёнрцгІ╪ж╙╣юЄ╚мЁ╣дд╬м╟юМбшхон╙фСр╣╡╩дэспІл╟Её╛╨СюЄсжҐ╡пбд╬м╟юМбшё╛фСр╣р╙спр╩╦ЖЁє╟Её╛х╩╨СсКфДкШЁє╟Е╨овВё╛ІЬуШ╦Жп╬ф╛╡Зр╣иЗл╛аЫфъй╝дЙЄЗ╡е©╙й╪Ґ╗а╒фПюЄ║ё
хн╨нпб╣диЗл╛тзҐ╗иХЁУй╪ҐвІнц╩спЁє╟Её╛І╪йгІл╟Её╛╣╚нйлБтзЄЄпбиЗл╛ж╝ЁУпХр╙╩Щ╪╚╡нсК╨овВЇ╒у╧ё╛╬║╧эйгІл╟Е╣╚тзсК╠Пхк╨овВ╣д╡Зр╣Ї╒у╧╧ЩЁлжп╦В╦ЖІл╟ЕжПҐ╔╣дящ╠ДЁиЁє╟Её╛вН╨С╣дд╬м╟╣дЁє╟ЕйгиЗЁєЁЖюЄ╣дІЬ╡╩йгфЄЄуфПюЄ╣д║ё
ЄсуБ╦ЖҐгІх╬м©иртж╙╣юн╙й╡цЄожтзжп╧ЗвЖп╬ф╛╣дм╩ффль╠Пюїдяё╛рРн╙фДкЭ╧З╪р╣дфСр╣тз╨овВжпЁиЁє║ён╙й╡цЄ╨ию╪р╙лЩцю╧З╣дё©йгтзЁєфз╨овВ╨С╩╔спхож╙ё╛т╦рБ╠кЄкеД╨огрюШрФр╩жб║ёожтз╣днйлБтзсзнрцгхГ╨нх╔сцІл╟ЕсКфДкШхк╨овВЇ╒у╧ё©р╩ЇҐцФё╛юМбшиоҐ╡втжВЄЄпбё╛бЩбЩҐБ╬ЖнйлБё╛╣╚©идэ╩А╠хҐобЩё╛рРн╙ЄЄпбр╡йгпХр╙уШ╦Ж╡Зр╣иЗл╛╣дпґвВ╡едэмЙЁиё╛хГ╧Шж╩йгфДжпр╩╩ЇІЬфДкШпґвВЇҐ╡╩еД╨оё╛дгЄЄпбм╩фф╬м╩АрЛЁё╪Хдя║ё
╩З╩Атзддё©п╬ф╛╡Зр╣╡╒ц╩спІЮиыдЙюЗйЇё╛╣╚йгп╬ф╛╡Зр╣╣ҐхГҐЯсжЁЖожпб╣д╦ОцЭё╛иор╩бж©ф╪╪╦ОцЭц╩сп╦оиоё╛╣╚обр╩бж©ф╪╪╦ОцЭйгнрцгпХр╙╧ьв╒╣дё╛кЫртҐ╡мД╣ю╡едэЁ╛Ё╣║ёожтзнрцгкДх╩бЩё╛╣╚йгр╡╡╩сц╬зи╔ё╛рРн╙мД╣ю╨эІЮё╛фДжпр╩╦ЖмД╣ю╬мйгхк╧єжгдэ║ёхк╧єжгдэмД╣ю╣дль╣Цйгй╡цЄё©кЭ╣диЗл╛╦Э╦ЄтсІЬ╡╩йг╦Э╪Р╣╔║ё╧Щх╔йг╣╔п╬ф╛╪фкЦ╣дй╠ЄЗё╛р╙вЯяґдіІШІ╗биё╛хГҐЯнрцг╬ґЁёл╦╣Ґ“діІШІ╗бийїпїак”║ё╠ххГ╦ВфСр╣мфЁЖ╣дSOCё╗о╣мЁ╪Іп╬ф╛ё╘ё╛р╩╦Жп╬ф╛вИюОцФспN╦ЖCPUё╛N╦ЖGPUё╛иУжаGPUё╛кЫртҐпрЛ╧╧╪фкЦё╛спм╗сц╪фкЦ╣╔т╙╨мв╗сп╪фкЦ╣╔т╙ё╛ІЬгрв╗сп╪фкЦ╣╔т╙╩╧уЩтз╡НрЛ╩╞║ё
╠ххГйж╩ЗюОв╗цен╙м╪оЯЄіюМё╛спр╩╦Ж╪фкЦ╣╔т╙ё╛в╗цен╙йсф╣ЄіюМйгаМр╩╦Ж╪фкЦ╣╔т╙ё╛кЫрт╬мпнЁир╩м╗сцЄЬІЮ╦Жв╗сц╣двИ╨оё╛уБ╦ЖҐА╧╧╪╚ЄСлАиЩакпїбйё╛Ґ╣╣макдэ╨дё╛кЫрткЭ╡╩пХр╙вН╦ъ╣д╪фкЦкыІхё╛╬мдэй╣ож╦Э╨ц╣дпї╧Шё╛уБр╡рБнІветзвЇгС╣╔п╬ф╛дэаіио╣др╙гС©иртҐ╣╣мё╛╡╩йг╣╔п╬ф╛вНсе╬мйгвш╨овНсеё╛уБяЫнр╧Зтз╣╔п╬ф╛ио╣дасйфйг╡╩йг╬м©иртцж╡╧ё©
аМр╩ЇҐцФё╛жп╧З╣дсейфтзддё©дэ╧╩хц╦ЭІЮ╣дЄСйЩ╬щсісц╩Щ╪╚╣ьх╔╨мхк╧єжгдэҐА╨оё╛схфДхГҐЯо╣мЁп╬ф╛спкЦЇ╗╧л╩╞╣дль╣Ц║ёюМбшиоҐ╡н╙дЁ╦Жппр╣в╗цея╣аЇппр╣йЩ╬щё╛╣ц╣Ґ╬ґ╧Щсе╩╞╣дкЦЇ╗ё╛ты╟якЦЇ╗╧л╩╞╣Ґс╡╪Ч║╒п╬ф╛жпё╛сц╧л╩╞╣дп╬ф╛х╔ЄіюМожй╣╣╠жпхк╧єжгдэнйлБ╩А╦Эсеё╛вН╣Дпм╣дюЩвс╬мйгвтІ╞╪щй╩п╬ф╛║ёльк╧юґн╙й╡цЄвтжВяпЇ╒╪щй╩п╬ф╛ё©тґрРтзсзвтІ╞╪щй╩кЫеЖ╣Ґ╣днйлБйгльрЛ╣дё╛хГ╧ШсцЄСа©втІ╞╪щй╩╣дйЩ╬щх╔я╣аЇё╛х╩╨С╣ц╣ҐуКІтвтІ╞╪щй╩се╩╞╧Щ╣дйЩ╬щё╛уБйгвН╦ъпї╣д║ё
жп╧ЗхГ╨нмД╣юЁ╛Ё╣ё©о╣мЁп╬ф╛рЛ╧╧╪фкЦй╠ЄЗё╛дэ╧╩╨еуыс╣спйЩ╬щ╣д╩З╧╧╡нсКтєя╣аЇё╛х╩╨СсКс╣спп╬ф╛╪фкЦ╪э╧╧╣д╧╚к╬иНІх╨овВё╛уБяЫп╬ф╛╣джфтЛк╝фҐнЄ╠ьйгвН╨цё╛╣╚п╬ф╛я╣аЇ╣ддёпмйгвН╨ц╣дё╛вН╨СуШлЕSOCп╬ф╛╣до╣мЁйДЁЖдэаійгвНг©╣дё╛рюх╩сп╩З╩АйєЁЖ║ё
р╩ЇҐйгп╬ф╛фСр╣ё╛р╩ЇҐйгхк╧єжгдэфСр╣ё╛р╩ЇҐйгсісцдэ╧╩╡ЗиЗЄСа©йЩ╬щ╣дсісцфСр╣ё╛дэ╧╩сп╦ЭІЮ╣дйЩ╬щя╣аЇдёпмвН╨С╧л╩╞╣Ґс╡╪Чжпё╛дгжп╧З╬м╩Ав╙асйфн╙сейф║ёЄсвтІ╞╪щй╩ппр╣©ирт©Є╣двНгЕЁЧ║ёвтІ╞╪щй╩ппр╣спхЩюЮфСр╣ё╛р╩юЮйгвтІ╞╪щй╩уШЁ╣фСр╣ё╛╡ЗиЗЁ╣╡╒гриобЇ╡ЗиЗйЩ╬щ║ёаМр╩юЮйгп╬ф╛╧╚к╬ё╛╣зхЩюЮжВр╙йгхк╧єжгдэ╧╚к╬║ёвтІ╞╪щй╩япЇ╒╧╚к╬рю©©с╡╪Чё╛м╗╧ЩйЩ╬щя╣аЇс╡╪ЧхМ╪Чо╣мЁё╛й╧╣цвтІ╞╪щй╩дэаілАиЩё╛вН╨СуФуЩдэ╧╩й╣ожвтІ╞╪щй╩дэаівЦ╧╩сепЦ║ёвтІ╞╪щй╩йгхк╧єжгдэ╣дй╬ЇІптЇІюЩё╛уБжждёйҐсі╦цЁЖожтз╦В╦Жппр╣аЛсРжпё╛хн╨нспвЦ╧╩йЩ╬щ╣дппр╣аЛсРІ╪сі╦цртЄкн╙ЇІйҐё╛дгжп╧З╬мсп©идэв╙асйфн╙сейф║ё
нрхон╙уБ╣хсзжп╧ЗҐХжЗЄСа©ппр╣йЩ╬щсісцфСр╣╣д╡нсКюЄ╟ОжЗнрцгтзо╣мЁп╬ф╛╡ЦцФйєЁЖё╛╡╩╬юҐАсз7дицвё╛©идэ48дицвм╛яЫ╧╩сцё╛хф©╙╣╔п╬ф╛╣дкю╬жё╛м╛й╠дэ╧╩й╧╣цсісцфу╪╟ё╛тзо╣мЁп╬ф╛иовЖ╨мсісц╣диНІхҐА╨оё╛пнЁи╩ЫсзйЩ╬щсе╩╞╣дкЦЇ╗ё╛╧л╩╞╣Ґп╬ф╛ппр╣╣дҐБ╬ЖЇҐ╟╦жпё╛Ґ╚йгуБр╩бжп╬ф╛╬╨уЫ╣д╨кпд║ё
юЄтЄё╨лзяІ©ф╪╪
оЮ╧ьндуб
- ҐТв╔йЩ╬щр╙кь╪шж╣╩╞ об╨цйЩвж╬ґ╪цЇ╒у╧охйжфЕ
- ҐТв╔йЩ╬щр╙кь╪шж╣╩╞ об╨цйЩвж╬ґ╪цЇ╒у╧охйжфЕ
- оР║╟пб║╠ІЬпп рт║╟пб║╠лАжй жп╧З╬ґ╪цпбІ╞дэеЛех
- Ґ╩м╗аЛсРхк╧єжгдэЇ╒у╧І╔╡ЦиХ╪фҐ╚ЁЖ
- хкпн╩ЗфВхк║╟╪скыеэ║╠ ╧Фдё╩╞сісцьҐпХй╣ож║╟хЩм╩фф║╠
- хЩ╡©цеЇ╒ндмфҐЬ╣Гвспео╒жфтЛр╣йЩвж╩╞в╙пм
- ╬шҐ╧нЕЄСжь╣ЦаЛсР 8╡©цеЇ╒нд╪с©ЛйЩжг╧╘сіаЄЇ╒у╧
- ╧єпе╡©╣хкд╡©це╡©йП©╙у╧2025дЙ║╟╟ыЁ║мРфС║╠ЄСжпп║фСр╣хзм╗ІтҐс╩НІ╞
- ╧єр╣╩╔а╙мЬ╨кпд╡Зр╣╧ФдёЁ╛1.5мРрз
- г©╩╞пбпм╧єр╣╩╞бли╚╣ви╚ ╧ЗЁё╩А╡©йПмфҐЬжфтЛр╣бли╚╣мл╪Ї╒у╧
-

╧ыЇҐ╧╚жз╨е
-

╧ыЇҐйсф╣╨е
-

╧ыЇҐп║ЁлпР
-

╧ыЇҐІІрТ╨е
-
 сйоД
сйоД
wic@wicongress.org
-
 ЄС╩А╧ымЬ
ЄС╩А╧ымЬ
www.wicongress.org.cn
-
 400ххоъ
400ххоъ
400-019-0516
-
 вия╞ххоъ
вия╞ххоъ
022-83608031


